Introdução e visão geral sobre compiladores
A construção de compiladores abrange diversas áreas de estudo em Ciências da Computação, como por exemplo conceitos de Linguagens de Programação, Arquitetura de Máquina, Algoritmos e Engenharia de Software. Nesse capítulo será apresentado uma introdução ao processo de compilação mostrando uma visão de alto nível da estrutura de um compilador.
As linguagens de programação e a arquitetura de computadores evoluem e estão cada vez mais sofisticados. O desafio dos projetistas de compiladores é criar algoritmos mais eficientes que visem obter um melhor desempenho no uso de memória e processamento.
Conhecer como um compilador funciona é essencial para entender a ligação entre Engenharia de Software, Linguagens de Programação, Sistemas Operacionais e Arquitetura de Computadores.
Nessa primeira parte do ebook vamos apresentar as etapas envolvidas no processo de compilação e como elas se relacionam entre si, com o objetivo de gerar um programa executável.
O Compilador
O compilador é um software complexo que converte uma linguagem fonte, ou linguagem origem, em uma linguagem destino, ou linguagem-objeto, ou seja, converte um programa originado de uma linguagem de programação para uma linguagem que possa ser entendida e executada por um computador. Durante a compilação são executadas tarefas que fazem a tradução de uma linguagem em outra.
Existem dois princípios fundamentais na construção de compiladores:
O compilador deve preservar o significado do programa a ser compilado; e
O compilador deve melhorar o programa de entrada de alguma forma perceptível.
As etapas de compilação são complexas e exigiam um esforço significativo, sendo que os primeiros compiladores eram escritos em código binário e salvos na memória ROM. Hoje nós temos um conjunto de ferramentas que facilitam a criação e manutenção de compiladores, muitas dessas ferramentas são escritas em linguagem como Java, C e C++ e já automatizam boa parte da construção de um compilador.
Essas ferramentas geram códigos que podem ser incluídos no projeto do compilador. Um exemplo são os geradores de analisadores léxicos, que com base em expressões regulares geram um algoritmo capaz de identificar os elementos léxicos de uma linguagem de programação.
O compilador precisa traduzir um conjunto infinito de programas escritos em uma linguagem de programação e o resultado desse processo deve ser um código eficiente que deve ser executado em diversas arquiteturas de processadores.
Um conceito muito importante no estudo de compiladores é a otimização, que se refere as atentivas de produzir um compilador que gere um código mais eficiente. Essa é uma etapa cada vez mais importante e complexa devido à grande variedade de arquiteturas de processadores. O tempo de compilação é outro fator muito importante que deve ser levado em consideração durante o desenvolvimento de um compilador.
Linguagens de programação
Podemos definir uma linguagem comumente chamada de língua ou idioma como um meio de comunicação entre pessoas. Em programação definimos a linguagem como o meio de comunicação entre o pensamento humano e as ações de um computador.
Todo o software executado em um computador foi escrito em alguma linguagem e antes que ele possa executar instruções diretamente no processador, um outro programa deve ser utilizado para traduzir essa linguagem em um formato que possa ser entendido e executado pelo computador, esse programa é chamado de compilador.
As linguagens de programação são projetadas para permitir que seres humanos expressem processos computacionais em uma sequência de operações, tal como ler um arquivo e imprimir o seu conteúdo em algum dispositivo, numa impressora por exemplo.
Os programas executados no computador são sequências de 0 e 1 que representam valores inteiros, ponto flutuante, strings, etc., ou ainda instruções que indicam o que o computador deve fazer. A memória do computador é dividida em partes que possuem endereços únicos, todo o programa armazenado na memória é executado pela CPU que possui registradores que guardam dados temporários utilizados em operações.
Pense na seguinte situação: para somar o número armazenado no endereço de memória $000011 com o número armazenado no endereço de memória $000012 é necessário:
- copiar o conteúdo da memória
$000011para um registrador A; - copiar o conteúdo da memória
$000012para um registrado B; - somar o conteúdo de A e B e copiar o resultado para o endereço de memória
$000013.
Esse processo certamente é muito mais complexo do que simplesmente executar o comando c = a + b em uma determinada linguagem de programação.
Uma linguagem de programação é considera de alto nível quando sua representação está próxima do domínio da aplicação e do problema a ser resolvido. Os computadores por sua vez possuem sua própria linguagem denominada de baixo nível ou linguagem de máquina.
O processo de tradução de uma linguagem de alto nível para linguagem de baixo nível é feito através de softwares conhecidos como compiladores e tem como entrada uma linguagem fonte, alto nível, e como saída uma linguagem-objeto, baixo nível.
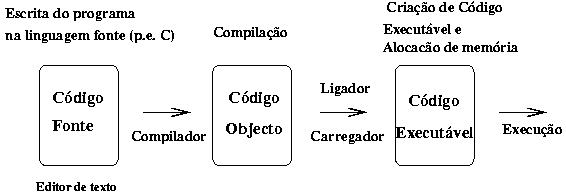
Na imagem acima podemos ver um diagrama que representa o processo de compilação, onde a entrada é um programa fonte e a saída é um programa objeto. Posteriormente, outros processos estão envolvidos na compilação, como por exemplo, o Ligador e o Carregador que criam o programa executável e auxiliam a sua execução.
As linguagens de programação podem ser classificadas em 5 gerações:
- 1ª linguagens de máquina – baixo nível.
- 2ª linguagens simbólicas ou montagem (Assembly) – baixo nível.
- 3ª linguagens orientadas a usuário – alto nível.
- 4ª linguagens orientadas a aplicação – alto nível.
- 5ª linguagens de conhecimento – alto nível.
Nos primórdios da computação os computadores eram programados em linguagem de máquina, 1ª geração, utilizando notação binária, dessa forma os algoritmos eram complexos e de difícil implementação. A 2ª geração denominada de linguagens simbólicas ou de montagem, foi utilizada para minimizar a complexidade da 1ª geração e utilizavam mnêmicos que substituíam as instruções binárias. As instruções eram convertidas em código de máquina antes de serem executados, esse processo é conhecido como montagem.
As linguagens de 3ª geração são voltadas para a solução de problemas específicos, por exemplo, o uso em aplicações comerciais e cientificas e esse momento surgem linguagens como COBOL, Pascal, Ada, FORTRAN, etc. Essas linguagens são classificas como procedimentais, declarativas, imperativas, lógicas, orientadas a objetos, etc. e os programas descrevem como os problemas serão resolvidos através de instruções denominadas: entrada/saída; cálculos aritméticos; cálculos lógicos e controle de fluxo.
As linguagens de 3ª geração foram projetadas para serem utilizadas por profissionais específicos, conhecidos como engenheiros de software ou simplesmente programadores. Já as linguagens de 4ª geração formam projetadas para serem utilizadas por usuários finais, sendo de fácil utilização permitindo que os próprios usuários possam resolver os seus problemas. Exemplos são: Excel; Access; SQL, etc. As linguagens de 5ª geração são utilizadas em programas de inteligência artificial simulando comportamentos inteligentes, como exemplo temos o PROLOG.
Cada vez mais os compiladores e as linguagem de programação assumem tarefas que antes eram de responsabilidade do programador, como por exemplo, gerenciamento de memória, verificação de tipos e execução paralela.
Através das linguagens de programação, consegue-se:
- Facilidades para se escrever programas;
- Diminuição do problema de diferenças entre máquina;
- Facilidade de depuração e manutenção de programas;
- Melhoria da interface homem/máquina;
- Redução no custo e tempo necessário para o desenvolvimento de programas;
Os primeiros passos para tornar a linguagem mais inteligível por humanos ocorreu na década de 50 com o desenvolvimento de linguagens simbólicas ou assembly. As instruções em Assembly representavam mnemônicos das instruções de máquina, mais tarde surgiram ferramentas conhecidas como macro assemblers que permitiam abreviaturas parametrizadas de uma sequência de instruções Assembly.
O surgimento das linguagens de programação como o FORTRAM e Cobol influenciaram o desenvolvimento de compiladores pois permitiam que construções de alto nível fossem possíveis de serem escritas de forma mais fácil. Posteriormente, com o surgimento de novas linguagem de programação com recursos cada vez mais inovadores, os compiladores se tornaram ferramentas muito mais sofisticadas.
Os programadores que utilizam linguagem de baixo nível têm mais controle sobre a execução de seus programas e podem produzir um código mais eficiente, mas esses programas são difíceis de serem escritos e executados em outras máquinas.
Com a evolução dos compiladores os programas escritos em linguagens de alto nível puderam ser otimizados para que fossem tão eficientes quanto programas escritos em linguagens de baixo nível. Linguagens de alto nível possuem recursos como laços, tipos de dados, controle de fluxo, etc. que facilitam a escrita de programas. Esses recursos são traduzidos para linguagens de baixo nível e executadas diretamente nos processadores através de instruções de máquina.
A criação de uma linguagem de programação depende do domínio da aplicação a que ela se propõe e isso também é um motivador para o surgimento de novas linguagens. Embora muitas tenham surgido com propósitos específicos, é comum uma linguagem ter muitas características e ser empregada em vários domínios de aplicação.
Veja no quadro abaixo alguns exemplos de domínios de aplicação e suas necessidades.

Muitas vezes temos que tomar a decisão de utilizar uma determinada linguagem de programação em um projeto, embora possa parecer fácil aprender uma nova linguagem, obter um nível considerável de expertise não é trivial. Não existe uma linguagem melhor ou pior e não é confortável fazer comparações diretas, o processo de escolha de uma linguagem deve analisar os recursos que cada uma oferece como solução aos problemas que o domínio da aplicação possui.
Quando geramos um compilador para uma linguagem de programação nós já temos uma linguagem que pode ser utilizada e manutenida, vamos supor que criamos uma linguagem chamada Legal, essa linguagem foi concebida com base em uma já existente, Python por exemplo - uma característica muito comum no surgimento de uma nova linguagem é ela ser proposta com base em outras - é importante ressaltar que, quando a linguagem Legal já estiver completa e com ela pudermos gerar seu próprio compilador, nós teremos um ciclo autossuficiente.
Tradutores
Os tradutores são sistemas que aceitam como entrada um programa escrito em uma linguagem e produzem como resultado um programa equivalente na mesma linguagem ou em linguagens diferentes. Os tradutores podem ser classificados em:
- Montadores: também chamados de assemblers, eles mapeiam instruções em linguagem simbólica para instruções em linguagem de máquina. Disassemblers ou desmontadores fazem o processo inverso.
- Macro assemblers: funcionam da mesma forma que os montadores, porém podem ser criados “macros” que representam uma sequência de comandos em linguagem simbólica.
- Compiladores: mapeiam programas escritos em linguagem de alto nível para linguagem simbólica ou de máquina.
- Pré-compiladores: também chamados de pré-processadores ou filtros, são programas que estendem a sintaxe de uma linguagem de alto nível com o objetivo de fazer a conversão entre duas linguagens de alto nível.
- Interpretadores: Possuem como entrada uma linguagem intermediária ou a própria linguagem fonte, e um programa compilado produz o efeito de execução.
Compiladores vs. Interpretadores
Diferente do compilador o interpretador recebe como estrada uma especificação executável e produz como saída, a execução dessa especificação. Linguagens como PHP, Scheme, Python são interpretadas.
Um interpretador pode ser entendido como um processo que, ao invés de visar um conjunto de instruções de um processador, visa produzir o efeito de sua execução. Eles normalmente interpretam uma representação intermediária do programa fonte.
No esquema abaixo podemos ter uma ideia macro das diferenças de funcionamento de um compilador e um interpretador.
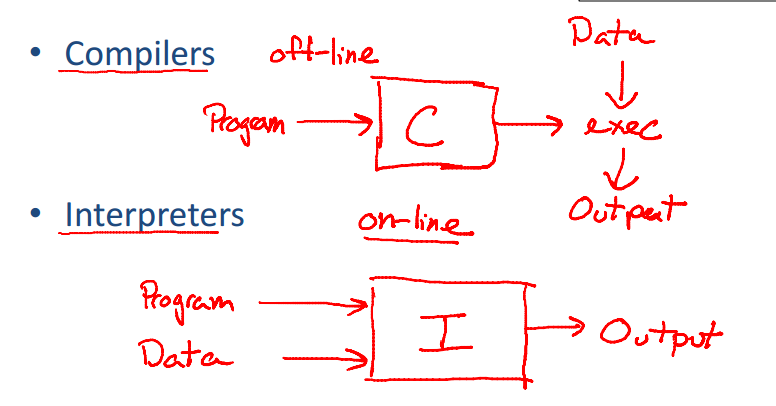
Os compiladores e interpretadores possuem muitas características em comum pois podem executar as mesmas tarefas, como por exemplo, analisar um programa e determinar se ele é válido ou não, porém os interpretadores são um tipo de tradutor no qual, algumas fases do compilador são substituídas por um programa que executa o código produzindo o seu efeito.
Um caso muito interessante é o da linguagem Java que combina compilação e interpretação. Temos o processo de compilação que gera um formato de código chamado de bytecode, e o processo de interpretação feito do bytecode pela Java Virtual Machine ou JVM. Outro detalhe de implementação feito na JVM e em muitos interpretadores é um processo chamado de JIT - Just in Time - que permite que algumas instruções, as mais utilizadas, sejam compiladas para código de máquina a fim de otimizar a sua execução.
O interpretador pode ser divido em dois tipos:
- Interpretador puro: cada instrução é "quebrada" em tokens, analisada, verificada semanticamente e interpretada cada vez que é executada. Como exemplo temos interpretadores de comandos shell.
- Interpretadores mistos: traduzem todo o script em código intermediário e depois interpretam esse código.
Um programa-objeto gerado por um compilador é muito mais rápido do que um programa executado por um interpretador, porém, um interpretador oferece melhores opções para diagnosticar erros, pois executa instrução por instrução.
Estrutura de um compilador
O processo de compilação é muito complexo, existindo uma estrutura básica que divide esse processo em fases, essas fases estão representadas por duas tarefas conhecidas como análise e síntese.
Essa divisão de fases tem como objetivo dar uma visão explicita e detalhada do processo de compilação. A tarefa de análise também chamada de front-end divide o programa fonte em partes e impõe uma estrutura gramatical sobre elas, uma das principais responsabilidades da tarefa de análise é garantir que a sintaxe e semântica do programa fonte estejam corretos. A tarefa de síntese constrói o programa objeto a partir da representação criada na tarefa de análise. A síntese é conhecida como back-end.

É importante destacar que esse estrutura dividida em seis fases é apenas uma representação didática e tem como objetivo demostrar como o compilador funciona, outras literaturas podem apresentar outros modelos com mais ou menos etapas.
Caso o compilador tenha sido cuidadosamente projeto podemos produzir compiladores de diferentes linguagens fonte para diferentes máquinas alvo, combinando diferentes estruturas de front-end para um único back-end ou um único front-end para diferentes back-ends.
O processo de compilação inicia com o analisador léxico que varre todo o programa fonte e transforma o texto em um fluxo de tokens, e nessa fase é criada a tabela de símbolos. Logo em seguida vem a análise sintática que lê o fluxo de tokens e valida a estrutura do programa criando a árvore sintática. A terceira fase é a análise semântica que é responsável por garantir as regras semânticas. Todas essas fases fazem parte da tarefa de análise.
A próxima fase e a geração de código intermediário, que cria uma abstração do código, logo após vem a fase de otimização do código e por fim, a geração do código objeto que tem como objetivo gerar o código de baixo nível baseado na arquitetura da máquina alvo. Essas fases fazem parte da tarefa de síntese.
Termos
1 Desmontador: também chamado de desassembler faz o processo inverso ao montador, ou seja, pega o código de máquina e transforma em código Assembly.
2 Mnemônicos: são símbolos que substituem o padrão de bits. Como exemplo o ADD equivale a soma e em bits significa 00100011.
3 Tempo de compilação: é o intervalo de tempo de conversão de um programa fonte para um programa objeto. Já o programa objeto é executado no intervalo de tempo chamado tempo de execução.
4 Tradutores auto-residentes: ou self-resident translators geram códigos de máquinas hospedeiras nas quais eles mesmos executam.
5 Cross-compiling: é o processo de compilação que permite a um compilador compilar um programa para diversos processadores ou arquiteturas.
[ˆ6] Bytecode: é uma representação de código-fonte que será interpretada por uma máquina virtual.
[ˆ7] Açúcar sintático ou Syntactic sugar: É uma forma de tornar uma construção sintática mais expressiva e simples de ler sem afetar seu comportamento.